|
|
|
|



Next: 4.2.6 Shared memory communication
Up: 4.2 WRAPPER
Previous: 4.2.4 Machine model parallelism
Contents
Logical processors are assumed to be able to exchange information
between tiles and between each other using at least one of two
possible mechanisms.
- Shared memory communication. Under this mode of
communication data transfers are assumed to be possible using direct
addressing of regions of memory. In this case a CPU is able to read
(and write) directly to regions of memory ``owned'' by another CPU
using simple programming language level assignment operations of the
the sort shown in figure 4.5. In this way one
CPU (CPU1 in the figure) can communicate information to another CPU
(CPU2 in the figure) by assigning a particular value to a particular
memory location.
- Distributed memory communication. Under this mode of
communication there is no mechanism, at the application code level,
for directly addressing regions of memory owned and visible to
another CPU. Instead a communication library must be used as
illustrated in figure 4.6. In this case CPUs must
call a function in the API of the communication library to
communicate data from a tile that it owns to a tile that another CPU
owns. By default the WRAPPER binds to the MPI communication library
Message Passing Interface Forum [1998] for this style of communication.
The WRAPPER assumes that communication will use one of these two styles
of communication. The underlying hardware and operating system support
for the style used is not specified and can vary from system to system.
Figure 4.5:
In the WRAPPER shared memory communication model, simple writes to an
array can be made to be visible to other CPUs at the application code level.
So that for example, if one CPU (CPU1 in the figure above) writes the value 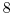 to
element
to
element 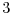 of array
of array 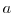 , then other CPUs (for example CPU2 in the figure above)
will be able to see the value
when they read from
, then other CPUs (for example CPU2 in the figure above)
will be able to see the value
when they read from 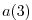 .
This provides a very low latency and high bandwidth communication
mechanism.
.
This provides a very low latency and high bandwidth communication
mechanism.
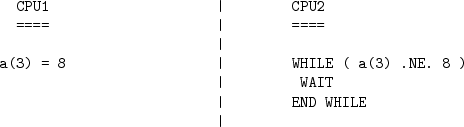 |
Figure 4.6:
In the WRAPPER distributed memory communication model
data can not be made directly visible to other CPUs.
If one CPU writes the value
to element
of array
, then
at least one of CPU1 and/or CPU2 in the figure above will need
to call a bespoke communication library in order for the updated
value to be communicated between CPUs.
 |
Next: 4.2.6 Shared memory communication
Up: 4.2 WRAPPER
Previous: 4.2.4 Machine model parallelism
Contents
mitgcm-support@mitgcm.org
| Copyright © 2006
Massachusetts Institute of Technology |
Last update 2011-01-09 |
 |
|