|
|
|
|



Next: 4.2.5 Communication mechanisms
Up: 4.2 WRAPPER
Previous: 4.2.3 WRAPPER machine model
Contents
Subsections
4.2.4 Machine model parallelism
Codes operating under the WRAPPER target an abstract machine that is
assumed to consist of one or more logical processors that can compute
concurrently. Computational work is divided among the logical
processors by allocating ``ownership'' to each processor of a certain
set (or sets) of calculations. Each set of calculations owned by a
particular processor is associated with a specific region of the
physical space that is being simulated, only one processor will be
associated with each such region (domain decomposition).
In a strict sense the logical processors over which work is divided do
not need to correspond to physical processors. It is perfectly
possible to execute a configuration decomposed for multiple logical
processors on a single physical processor. This helps ensure that
numerical code that is written to fit within the WRAPPER will
parallelize with no additional effort. It is also useful for
debugging purposes. Generally, however, the computational domain will
be subdivided over multiple logical processors in order to then bind
those logical processors to physical processor resources that can
compute in parallel.
Computationally, the data structures (eg. arrays, scalar
variables, etc.) that hold the simulated state are associated with
each region of physical space and are allocated to a particular
logical processor. We refer to these data structures as being owned by the processor to which their associated region of physical
space has been allocated. Individual regions that are allocated to
processors are called tiles. A processor can own more than one
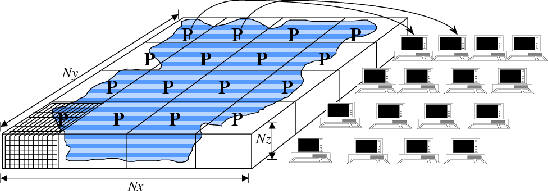
tile. Figure 4.3 shows a physical domain being
mapped to a set of logical processors, with each processors owning a
single region of the domain (a single tile). Except for periods of
communication and coordination, each processor computes autonomously,
working only with data from the tile (or tiles) that the processor
owns. When multiple tiles are alloted to a single processor, each
tile is computed on independently of the other tiles, in a sequential
fashion.
Figure 4.3:
The WRAPPER provides support for one and two dimensional
decompositions of grid-point domains. The figure shows a
hypothetical domain of total size
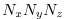 . This
hypothetical domain is decomposed in two-dimensions along the
. This
hypothetical domain is decomposed in two-dimensions along the
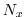 and
and 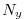 directions. The resulting tiles are owned by different processors. The owning processors
perform the arithmetic operations associated with a tile.
Although not illustrated here, a single processor can own
several tiles. Whenever a processor wishes to transfer data
between tiles or communicate with other processors it calls a
WRAPPER supplied function.
directions. The resulting tiles are owned by different processors. The owning processors
perform the arithmetic operations associated with a tile.
Although not illustrated here, a single processor can own
several tiles. Whenever a processor wishes to transfer data
between tiles or communicate with other processors it calls a
WRAPPER supplied function.
|
|
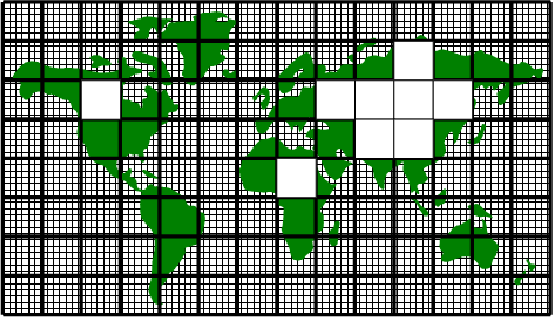
Tiles consist of an interior region and an overlap region. The
overlap region of a tile corresponds to the interior region of an
adjacent tile. In figure 4.4 each tile would own the
region within the black square and hold duplicate information for
overlap regions extending into the tiles to the north, south, east and
west. During computational phases a processor will reference data in
an overlap region whenever it requires values that lie outside the
domain it owns. Periodically processors will make calls to WRAPPER
functions to communicate data between tiles, in order to keep the
overlap regions up to date (see section
4.2.8). The WRAPPER functions can use a
variety of different mechanisms to communicate data between tiles.
Figure 4.4:
A global grid subdivided into tiles.
Tiles contain a interior region and an overlap region.
Overlap regions are periodically updated from neighboring tiles.
|
|
Next: 4.2.5 Communication mechanisms
Up: 4.2 WRAPPER
Previous: 4.2.3 WRAPPER machine model
Contents
mitgcm-support@mitgcm.org
| Copyright © 2006
Massachusetts Institute of Technology |
Last update 2011-01-09 |
 |
|